What is heap table | Full table scan

In this video we will discuss
- What is a heap table, how to create and when to use it.
- Along the way, we will understand the concept of Table Scan as well.
- We will also look at a simple example in action, where a full table scan is better from performance standpoint than using a table index.
- Finally, we will also discuss how to force the database query engine to use a specific index to find the data we are looking for.
- Understanding all these concept is very important when you are tuning SQL queries for better performance.
What is a heap table
Let's understand this with an example. Consider the following Employees table.
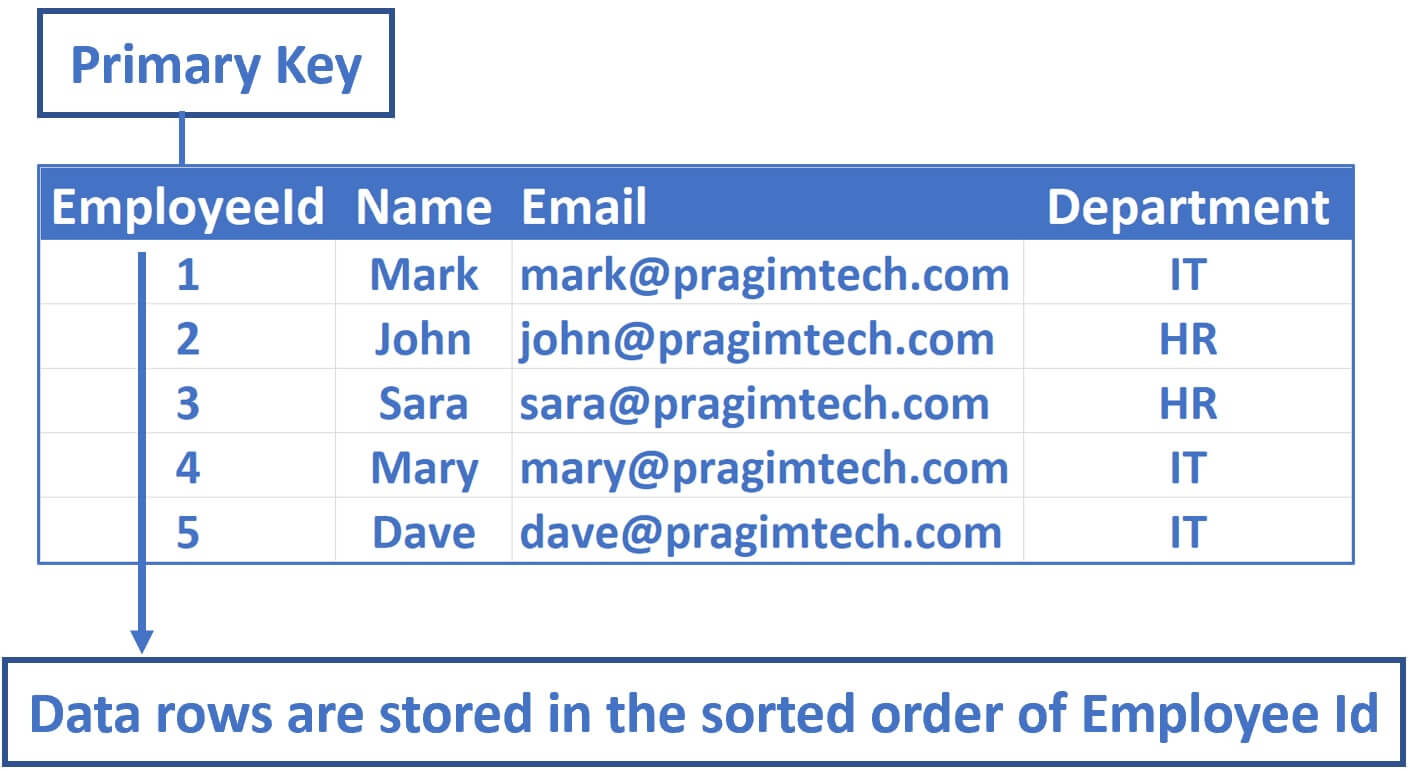
EmployeeId is the primary key, so by default a clusterd index on this column is created. This means the data rows that are physically stored in the Employees table are sorted by EmployeeId column.
What if we don't have a clustered index on a table?
Well, it is the clustered index that determines the order in which data rows are physically stored in a table. Without a clustered index, the data rows are not guaranteed to be in any specific order in the table. This kind of a table is called a heap. It may have one or more non-clustered indexes, but if it doesn't have a clustered index, then such a table is called a heap table or just heap. So, in short, a table without a clustered index is called heap.
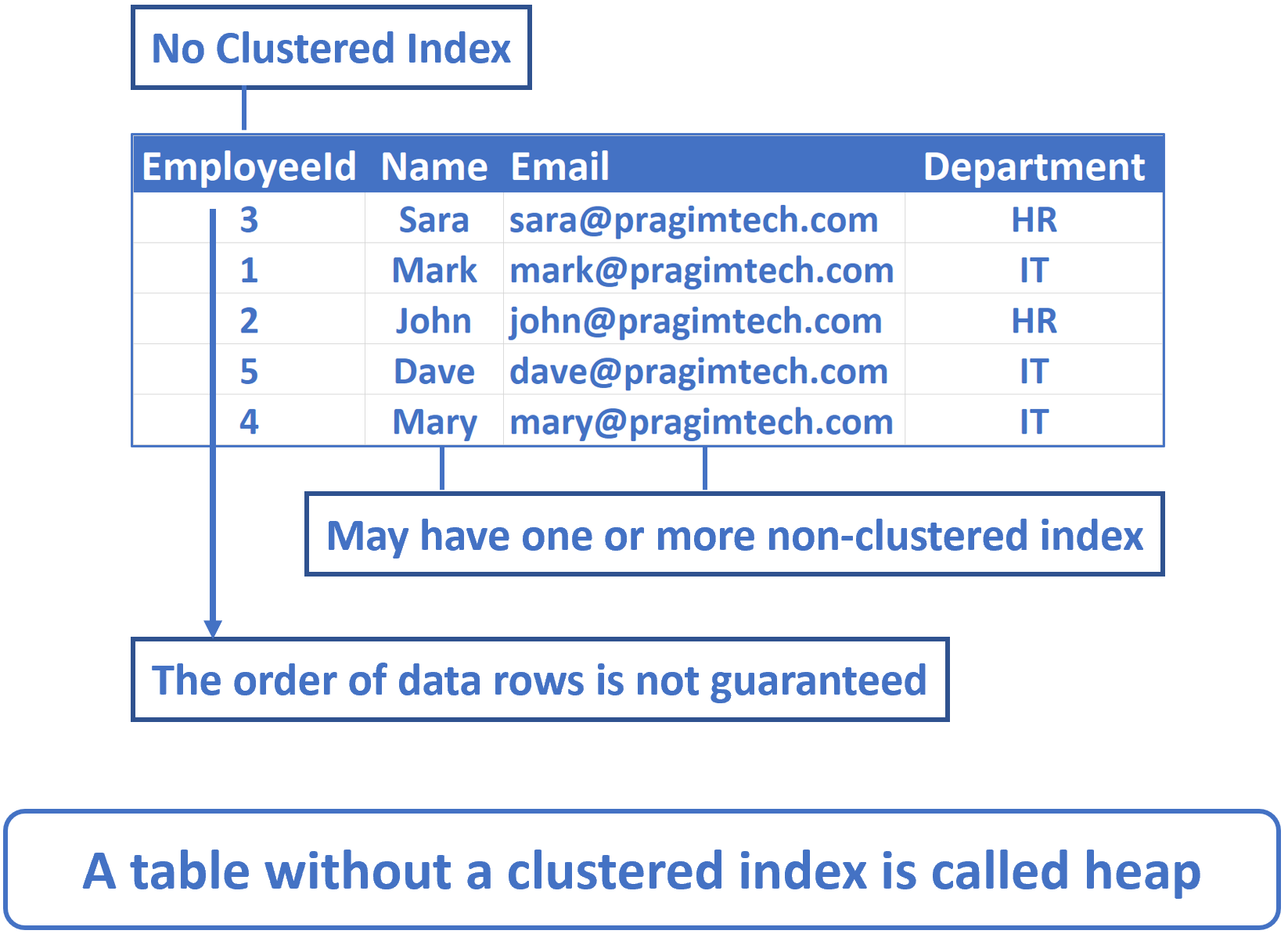
Heap table without non-clustered index
What happens when we select data from a heap. Will the database engine use Index Seek, Index Scan or Table Scan?
Well, it depends. We already know, a heap is a table without clusterd index, but it may have one or more non-clustered indexes. But for this example, let's assume the heap does not have any non-clustered indexes as well.
If there are no non-clusterd indexes on the heap, the search query uses Table Scan to find the data we are looking for. What is a table scan? Well, as the name implies, a table scan, scans every row in the table to find the row we are looking for. Let's look at this in action.
SQL Script to create Gender table
Notice we did not mark any of the columns as primary key and we also did not create a clsustered index explicitly. So the physical order in which data rows are stored in this table is not guaranteed. In a nut shell, this Gender table is a heap. We also did not create any non-clsusterd indexes.
Create Table Gender
(
GenderId int,
GenderName nvarchar(20)
)
Go
Insert into Gender values(1, 'Male')
Insert into Gender values(3, 'Not Specified')
Insert into Gender values(2, 'Female')Use sp_helpindex system stored procedure to check if a table has any indexes
sp_helpindex GenderNow, execute the following query with Include Actual Execution Plan turned on
Select * from Gender where GenderName = 'Male'From the execution plan, it's clear, a table scan is being used to find the data we are looking for.
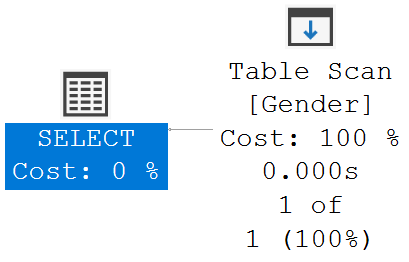
Notice, from the stats below, Number of rows read is 3 and Actual number of rows for all executions is 1. So, to get the 1 row we need, SQL server has to read all the 3 rows in the table.

Also notice, Estimated Subtree Cost is 0.0032853, which is not bad at all from performance standpoint. So, 3 key points to keep in mind here are the following.
- A table scan is used if there are no indexes to help a query that selects data from a table heap
- Table scan is not always bad from performance standpoint, especially if you have a table with very a few rows like this Gender table
- Even if there is an index on a very small table like this Gender table, SQL server might still end up using table scan. This is beacause a table scan provides better performance than using the index. Let's actually prove this last point.
Non-clusterd index on heap table
Create nonclustered index IX_Gender_GenderName
on Gender(GenderName)Execute the following query with Include Actual Execution Plan turned on
Select * from Gender where GenderName = 'Male'
Though we have a non-clustered index on GenderName column, SQL server is still using Table Scan instead of Index Seek. This is because the database engine knows Table Scan produces better performance than index seek as there are very few rows in the Gender table. So, another key point to keep in mind here is, if the table has very few rows and even if there is an index to help the query, the database engine might still end up performing a full table scan instead of using the index.
Force a query to use an index in sql server
SQL Server query optimizer selects the best execution plan for a query. However, if need be, we can force the query engine to use an index.
Select * from Gender with (Index(IX_Gender_GenderName))
where GenderName = 'Male'Index Seek is now used instead of Table Scan
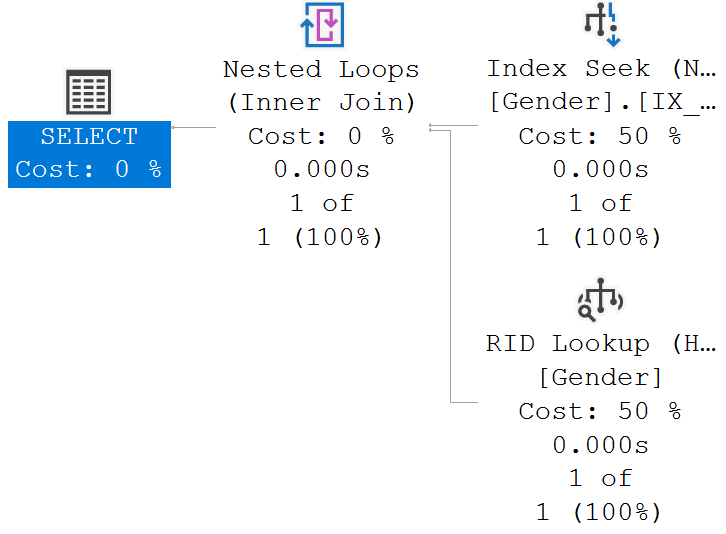
The overall SELECT statement Estimated Subtree Cost is 0.0065704

With the table scan, on the other hand, the overall SELECT statement Estimated Subtree Cost is 0.0032853

So, the bottom line is, we have better performance with table scan than using the index. Hence, the query optimizer chose table scan over using the index.
How are data rows stored in the heap
- Data is initially stored in the order in which is the rows are inserted into the heap table.
- However, the Database Engine can move data around in the heap to store the rows efficiently, so the order of data rows in a heap cannot be predicted.
- To guarantee the order of rows returned from a heap, you must use the ORDER BY clause in your query.
How to create and remove heaps

To create a heap, create a table without a clustered index. If a table already has a clustered index, drop the clustered index to return the table to a heap.
You already have a heap and to remove it, simply create a clustered index on the heap.
When to use a heap
- A heap can be used as a staging table for large and unordered insert operations. Because data is inserted without enforcing a strict order, the insert operation is usually faster than the equivalent insert into a table with clustered index.
- The table is small with just a few rows.
- Data is always accessed through nonclustered indexes.


© 2020 Pragimtech. All Rights Reserved.