How is data stored in SQL database
In this video we will understand how SQL Server stores data internally. As a software engineer this knowledge is very important, especially if you want to troubleshoot and fix SQL queries that are not performing very well from performance standpoint. Along the way we will also understand some of the common technical terms like the following. Understnading these terms is very important, especially if you are doing something related to sql server performance tuning.
- Data pages
- Root node
- Leaf nodes
- B-tree
- Clustered index structure
How is data physically stored in SQL Server
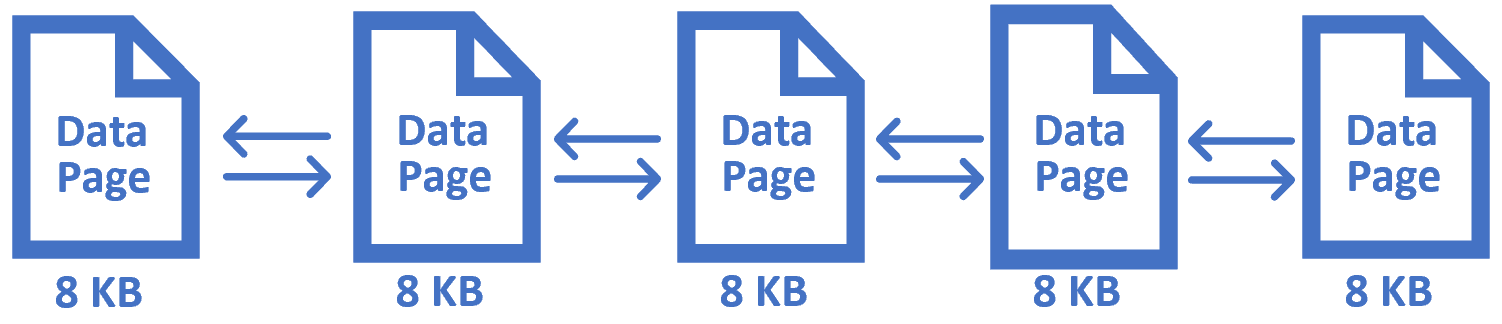
Have you ever wondered how SQL server physically stores table data internally? Well, data in tables is stored in row and column format at the logical level, but physically it stores data in something called data pages. A data page is the fundamental unit of data storage in SQL Server and it is 8KB in size. When we insert any data in to a SQL Server database table, it saves that data to a series of 8 KB data pages.
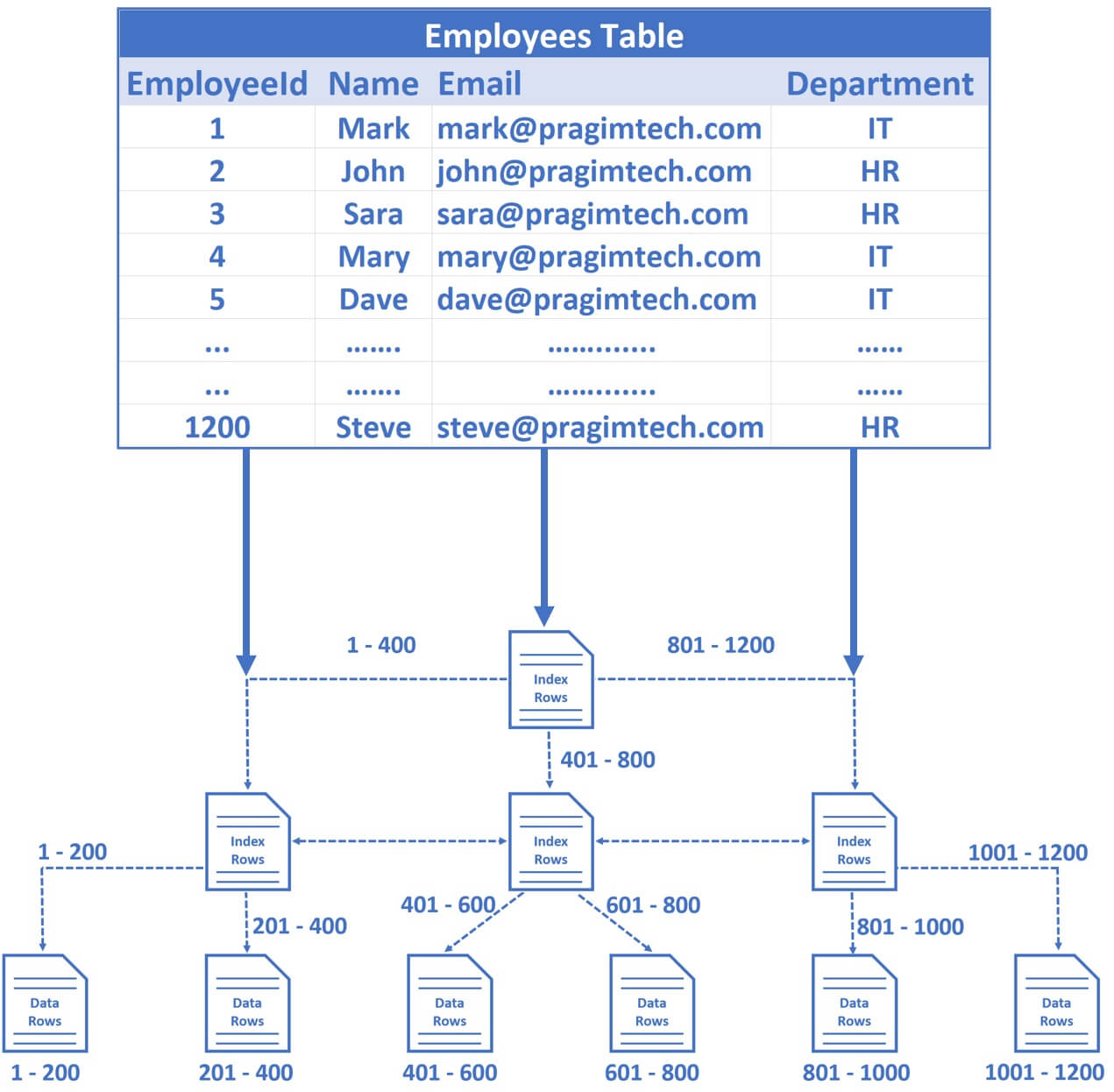
Data in SQL Server is stored in a tree like structure
Table data in SQL Server is actually stored in a tree like structure. Let's understand this with a simple example. Consider the following Employees table.
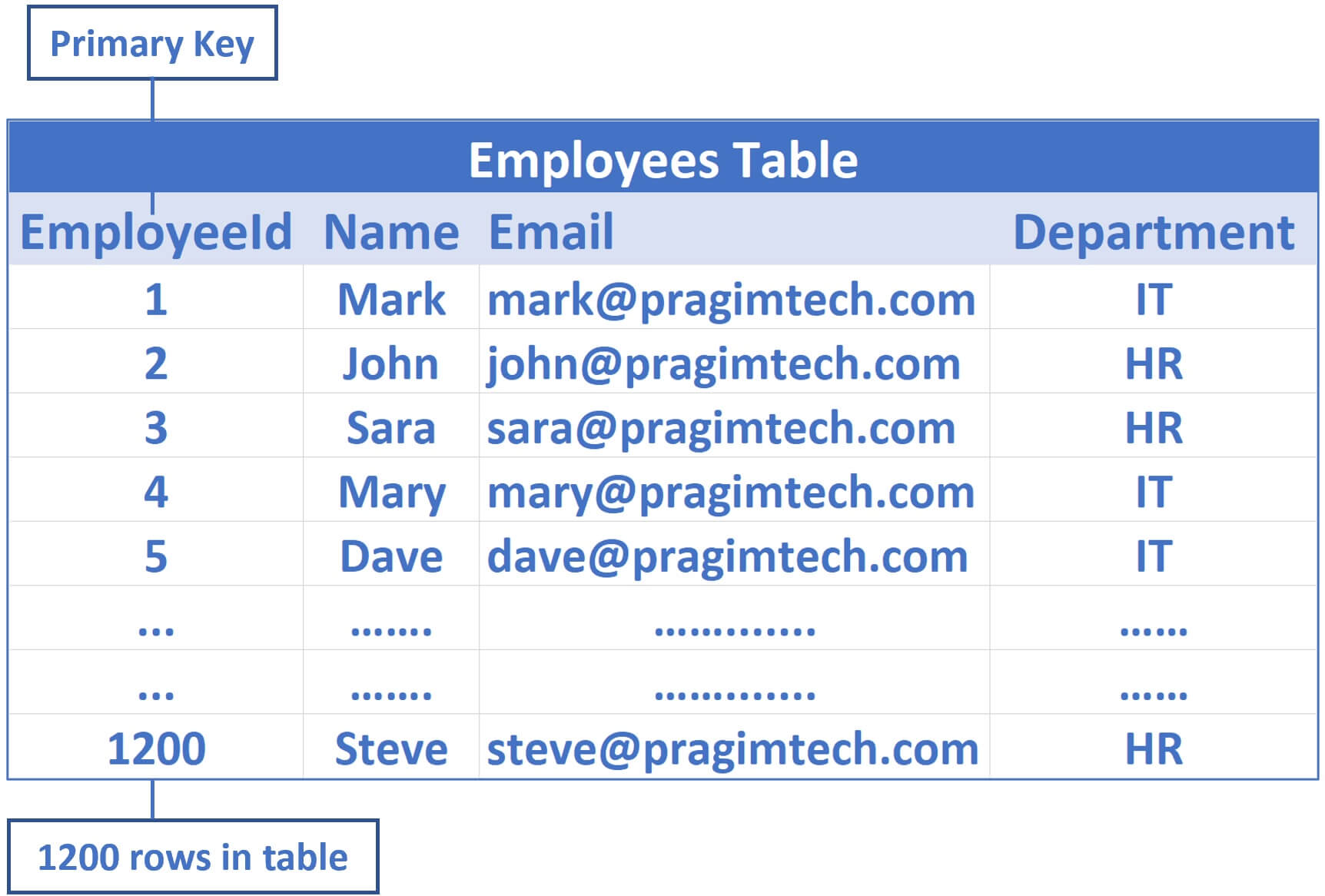
- EmployeeId is the primary key column
- So by default, a clustered index on this EmployeeId column is created
- This means the data that is physically stored in the database is sorted by EmployeeId column
Where is the data actually stored
Well, it is stored in a series of data pages in a tree like structure that looks like the following. This tree like structure is called B-Tree, index B-Tree or clustered index structure. All these 3 terms mean the samething.
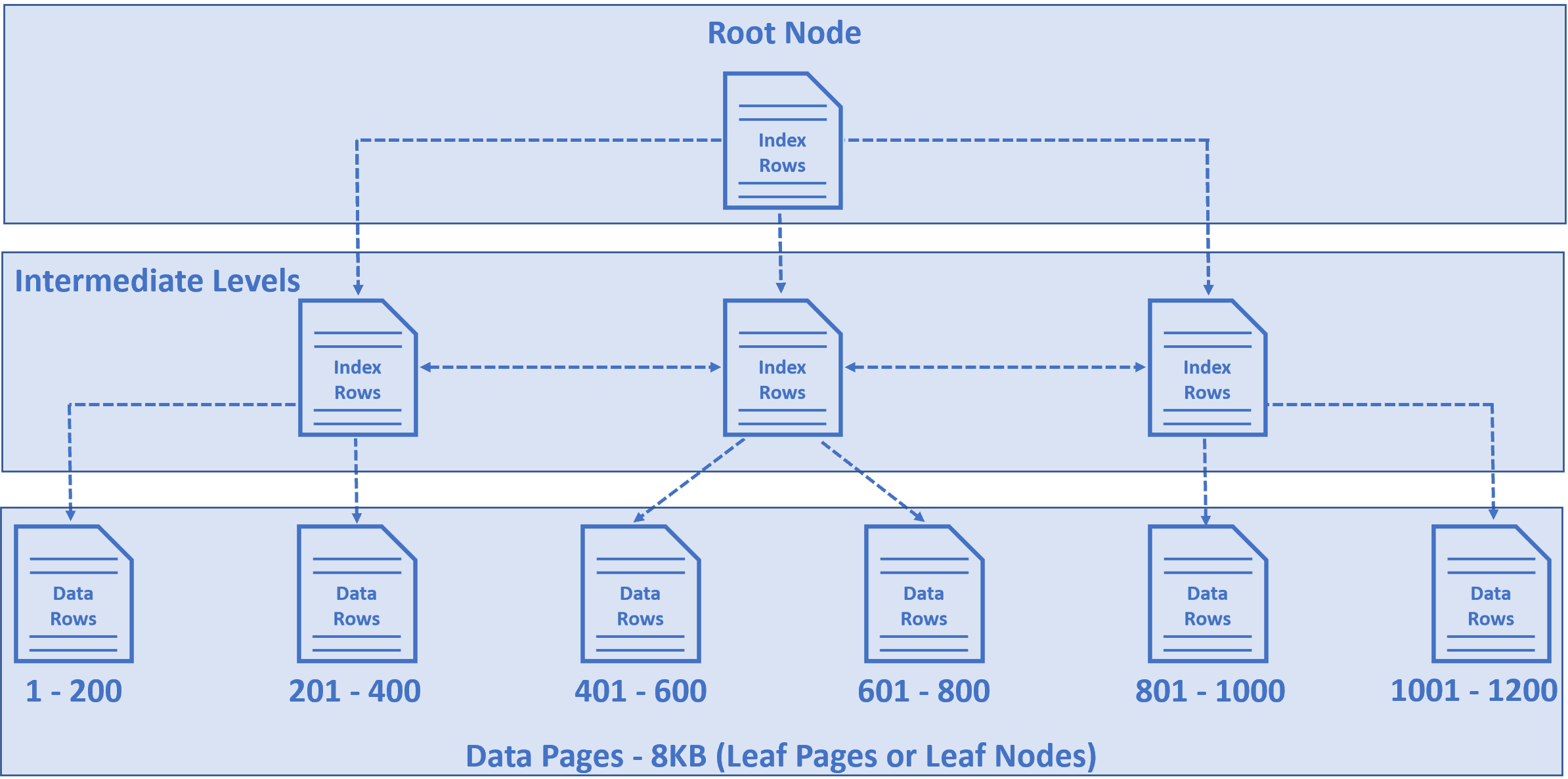
- The nodes that you see at the bottom of the tree are called data pages or leaf nodes of the tree and it is these leaf nodes that contain our table data.
- The size of each data page is 8 KB. This means, the number of rows that are stored in each data page really depends on the size of each row.
- For our example, let's say in this Employees table we have 1200 rows and let's assume in each data page we have 200 rows, but in reality depending on the actual row size we may have more or less rows, but for this example sake, let's assume each data page has 200 rows.
- Remember, the important point to keep in mind is, the rows in these data pages are sorted by EmployeeId column, because EmployeeId is the primary key of our table and hence the clustered key.
- So, in the first data page we have 1 to 200 rows, in the second 201 to 400, in the third 401 to 600, so on and so forth.
- The node at the top of the tree is called Root Node.
- The nodes between the root node and the leaf nodes are called intermediate levels.
- There can be multiple intermediate levels. In our example, we have just 1200 rows and to keep this example simple, I included just 1 intermediate level, but in reality the number of intermediate levels depends on the number of rows you have in the underlying database table.
- The root and and the intermediate level nodes contain index rows, and the leaf nodes (i.e nodes at the bottom of the tree) contain the actual data rows.
- Each index row contains a key value (in our case Employee Id) and a pointer to either an intermediate level page in the B-tree, or a data row in the leaf node.
- So the important point is, this tree like structure has a series of pointers that helps the database engine find the data quickly.
How SQL Server finds a row by ID
For example, let's say we want to find Employee row with EmployeeId = 1120. So the query is very simple, Select * from Employees where EmployeeId = 1120
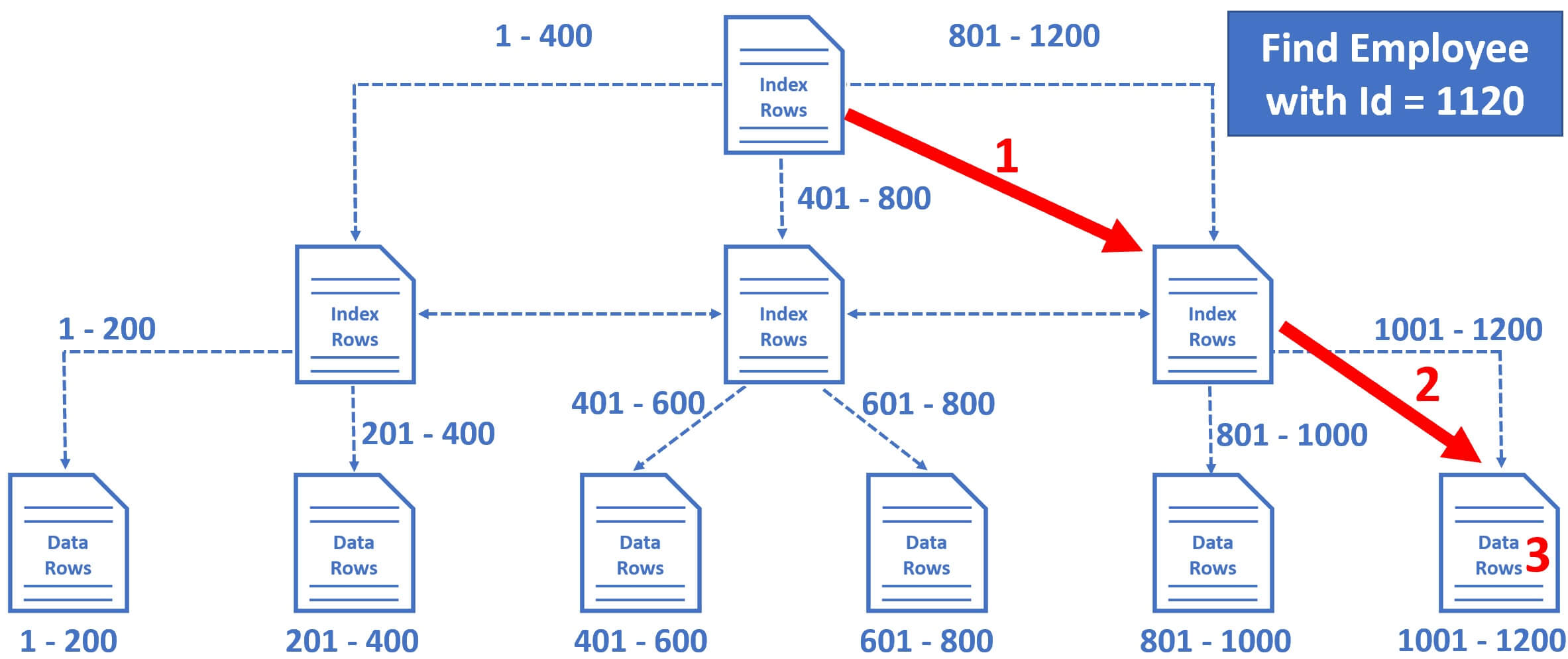
- So the database engine starts at the root node and it picks the index node on the right, because the database engine knows it is this node that contains employee IDs from 801 to 1200.
- From there, it picks the leaf node that is present on the extreme right, because employee data rows from 1001 to 1200 are present in this leaf node.
- The data rows in the leaf node are sorted by Employee ID, so it's easy for the database engine to find the employee row with Id = 1120.
Notice in just 3 operations, SQL Server is able to find the data we are looking for. So the point is, if there are thousands or even millions of records, SQL server can easily and quickly find the data we are looking for, provided there is an index that can help the query find data.
In this example, there is a clustered index on EmployeeId column, so when we search by employee id, SQL Server can easily and quickly find the data we are looking for. What if we serach by Employee name? At the moment, there is no index on the Name column, so there is no easy way for sql server to find the data we are looking for. SQL server has to read every record in the table which is extremely inefficient from performace standpoint. This is when we create a non-clustered index.
In our next video in this series, we will discuss how the index and table data is physically stored when we have both a non-clutered index and clustered index. We will also discuss index seek and index scan. Understanding these two concepts is very important especially when we are tuning sql queries for better performance. We will see all these practically in action in our next video, so please stay tuned.
If you are new to SQL Server indexes, we have already discussed them in detail in our SQL Server tutorial for beginners course. Please check out the videos from Parts 35 to 38. The following is the link.https://www.youtube.com/playlist?list=PL08903FB7ACA1C2FB


© 2020 Pragimtech. All Rights Reserved.